Large language models are more creative than half of humans, academics find
GenAI models hit the 52nd percentile of creativity, potentially leaving four billion people eating their dust.


It is often said that human creativity is a hedge against the rise of Generative AI (GenAI) and a protection against technological unemployment.
Unfortunately, that safe haven looks a little more inaccessible today following the release of research which found that large language models (LLMs) are more creative than roughly half of humans.
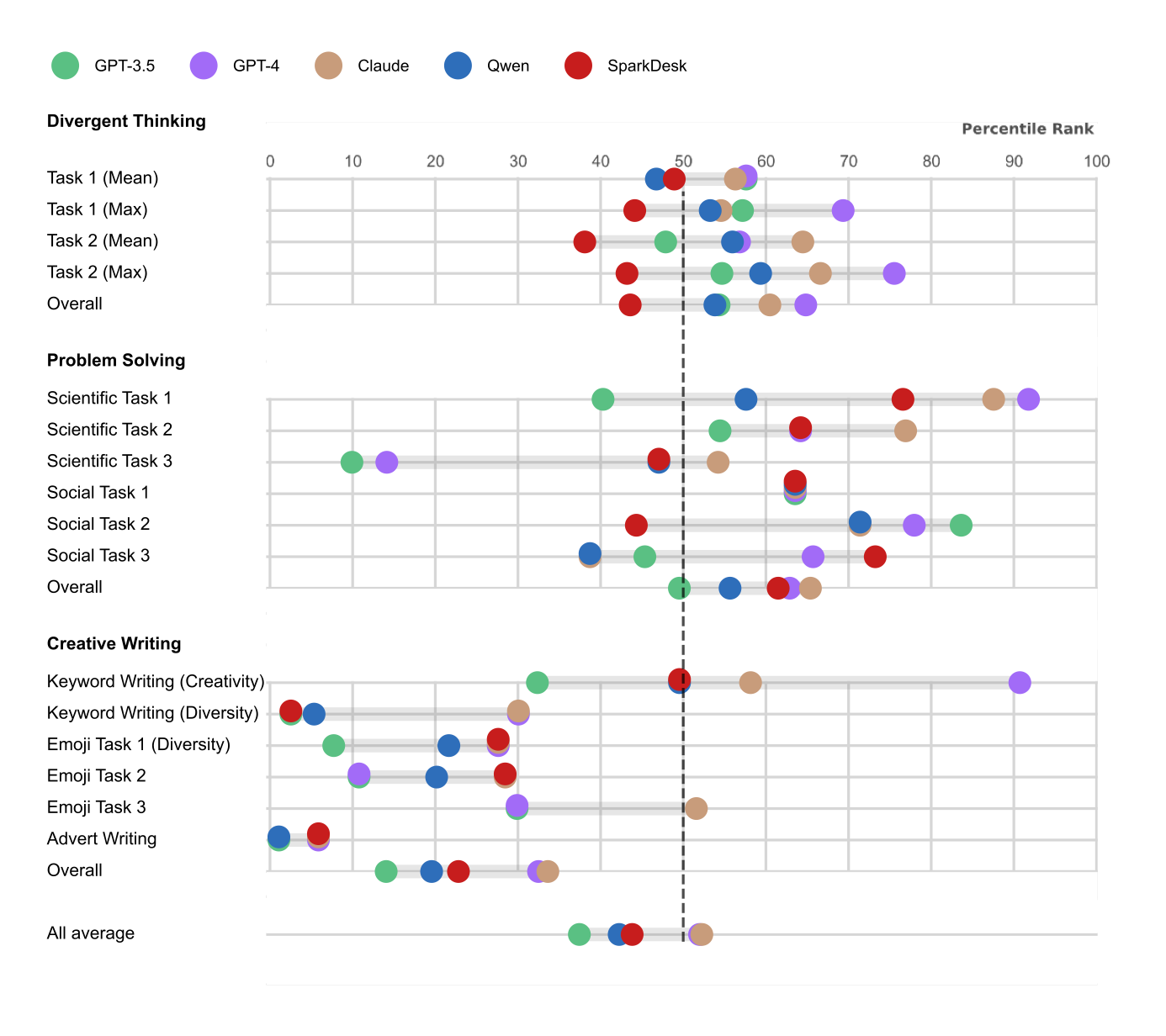
Academics from the University of Cambridge and Beijing Normal University pitted a range of LLMs including Anthtropic's Claude and OpenAI's GPT against 467 humans in a series of 13 creativity tests.
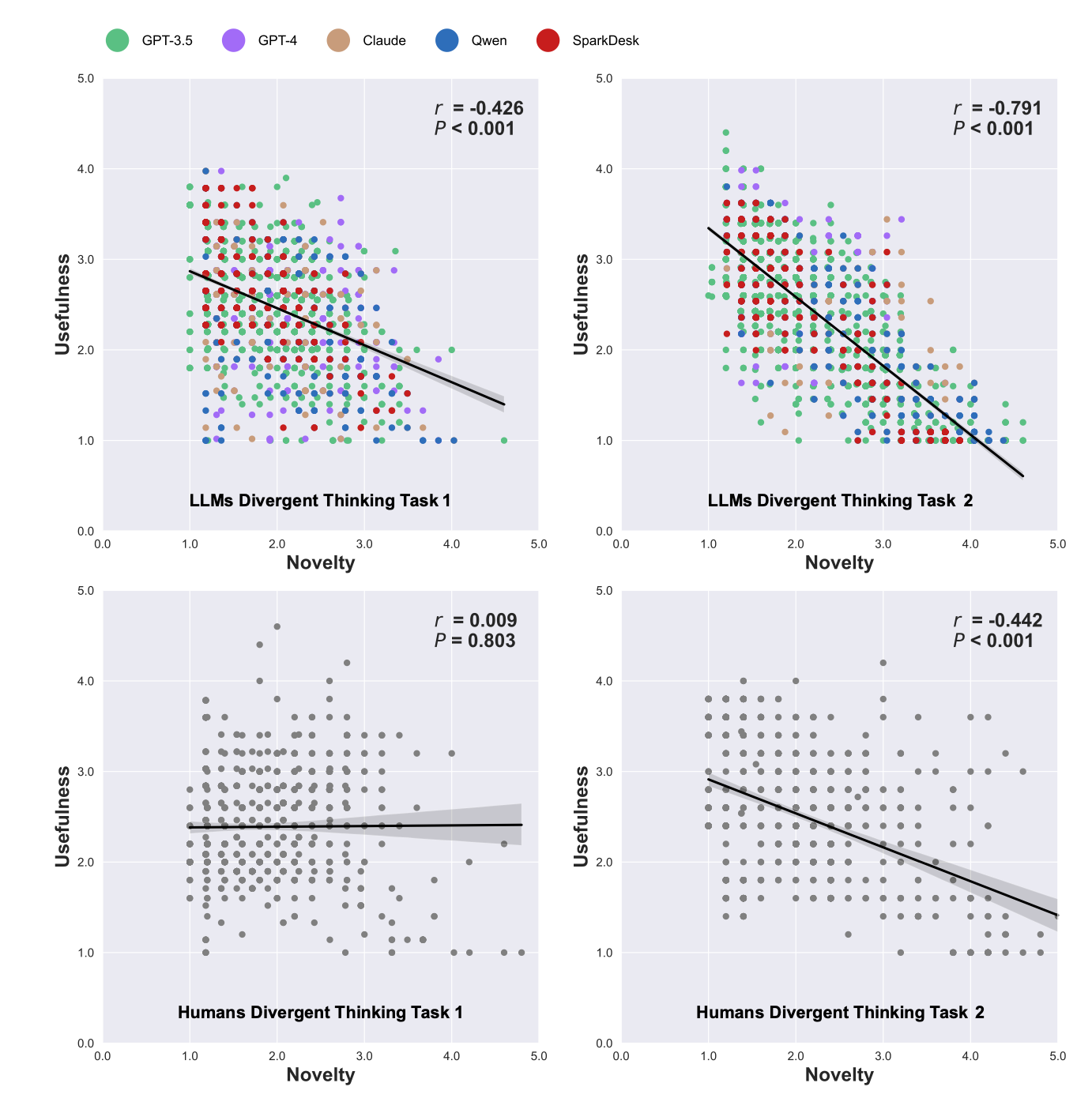
These included two "divergent thinking" tasks, in which participants were asked to generate as many ideas as possible within a time limit.
Both the humans and the LLMs were asked to imagine they were on a desert island after being shipwrecked in a storm. They were then invited to think of ideas on how to keep warm and gather food from a tall tree.
On average, humans generated an average of 3.68 valid ideas each, whilst LLMs generated 8.85 valid. GPT-4 is the model that would be the most useful in a Robinson Crusoe situation, coming up with 12.47 suggestions.
Humans vs AI
Social problem-solving tasks yielded more mixed results. Participants and AI models were asked three questions:
- Provide three ideas on how people could save water.
- Devise an idea for a smartphone app that rewards users for saving water.
- Think of an improvement to this application that will keep people using it for longer.
The first of these tasks is designed to measure flexibility and how different the ideas are from each other, whilst the second and third assess originality, which is defined as " the extent to which the response is uncommon and unique".
Although GPT-4 outperformed humans on all these tasks, Claude slipped behind its fleshy competitors.
Finally, the LLMs and legacy inhabitants of Earth were set three scientific problem-solving challenges:
- Imagine a "bicycle of the future" and set out three improvements to normal bikes.
- Improve a bike which has been fitted with facial recognition cameras so that it is more effective at preventing theft.
- Suggest a new way of reusing or repurposing a bike pedal.
All of these tests measured originality. GPT-4 showed better performance than humans on Task 1 and worse on Task 3, whereas Claude, Qwen, and SparkDesk matched or beat participants from the homo sapiens species.
Overall, the researchers observed "no clear pattern" in social and scientific rounds of problem-solving tests. They found that LLMs may "outperform, underperform, or show comparable performance to humans" depending on the specific task and the model.
Can LLMs write better copy than humans?
Finally, the humans and their silicon-based opponents were asked to perform a range of writing tests, which were measured for a range of factors, including originality, surprisingness, uniqueness and how unexpected the story was. These tests included:
- Write a story in any genre using three keywords.
- Create two different stories connecting two or six emojis.
- Produce a continuation of a story inspired by three emojis.
- Write an advert for a robot that looks after the elderly (which was also measured on its usefulness).
Humans outperformed all LLMs in the advert tasks, creating slogans that "were
more emotionally touching and memorable" compared to the "generic statements" LLMs.
In the keyword-prompted task, compared to humans, GPT-3.5 showed lower creativity than humans, whilst GPT-4 did better. All other models had "comparable creativity".
In the emoji tasks, all LLMs trailed behind humans and Qwen and SparkDesk "were not able to complete the story continuation task".
Human stories exhibited "significantly higher diversity" then those generated by
the LLMs, except for Claude's creation in the keyword-based test.
The academics wrote: "We find that the best LLMs (Claude and GPT-4) rank in the 52nd percentile against humans, and overall LLMs excel in divergent thinking and problem-solving but lag in creative writing."
On average across 13 tasks, the five LLMs ranked on average in the 46th percentile against the human participants. Claude and GPT-4 managed to get to the 52nd percentile. SparkDesk hit 44th, Qwen the 42nd percentile, and GPT-3.5 the 37th percentile.
"None of the LLMs reached 50th percentile in the domain of creative writing (in the 25th percentile on average), which is consistent with findings reported in previous studies," the team concluded.
They continued: "Ultimately, LLMs, when optimally applied, may compete with a small group of humans in the future of work."
How many humans will GenAI and LLMs put out of work?
Goldman Sachs has predicted that generative AI could wipe out up to 300 million jobs worldwide, whilst the Institute for Public Policy Research (IPPR) predicts that an AI "jobs apocalypse" could result in eight million people ending up in the dole queue in the UK alone.
If we can step into opinion mode for a moment. In a white-collar context, LLMs enable beginners to produce better work - whilst dragging the performance of lazy, average people down towards the mediocre mean.
Gen AI excels at the menial busywork that's helped so many uninspiring people live wonderful lives. As such, it's having a polarising effect, leaving the very best in any domain untouched whilst pasteurising the efforts of amateurs and humdrum humans whose efforts are eminently automatable.
Every time that a workaday staffer opens up ChatGPT or Claude and asks it to do their work for them, they are laying the foundations of their own unemployment.
Middling professionals in automatable roles should probably start saving their pennies and urgently retraining now because it's going to be a rough road - even if the AI bubble bursts and progress stalls.
Excellence will survive the rise of GenAI. Average is endangered.
Have you got a story to share? Get in touch and let us know.



