Beyond large AI: The rise of lean language models
"LLM model size competition is intensifying... backwards."


If you're trying to build a digital god, only the very biggest and most powerful data centre will do.
But if you're more concerned with improving your productivity at work or performing some other relatively small task, you don't necessarily need 100,000 GPUs to train an AI model to do your bidding.
Just over two years ago, OpenAI introduced the wider world to the concept of a large language model (LLM) when ChatGPT entered the record books as the fastest-adopted consumer app of all time. This year, there has been increasing attention paid to small language models, which require less data, energy, compute and even training time.
These models will not lead to the development of artificial general intelligence (AGI) or artificial superintelligence (ASI) unless, perhaps, large numbers of small models take advantage of swarm dynamics to create a decentralised intelligence.
We know that AGI will destroy humans' jobs. Yet lean language models, as we're calling them, have the potential to do the opposite and make working life better for real-life, flesh-bound workers.
Creating small language models
LLMs typically send requests to a centralised server. Small models, on the hand, often work independently.
In December, researchers at Princeton will demonstrate one method of creating "leaner" language models: a new algorithm called Caldera at the Conference on Neural Information Processing Systems (NeurIPS). It is a post-training compression algorithm that reduces the size of LLMs for deployment on memory-constrained devices, maintaining performance while optimizing storage and compute efficiency.
Caldera (which stands for Calibration Aware Low precision DEcomposition with low Rank Adaptation) works by "trimming redundancies" and "reducing the precision of an LLM’s layers of information".
“Any time you can reduce the computational complexity, storage and bandwidth requirements of using AI models, you can enable AI on devices and systems that otherwise couldn’t handle such compute- and memory-intensive tasks,” said Andrea Goldsmith, dean of Princeton’s School of Engineering and Applied Science and co-author of a paper on the algorithm.
Both AI models and the data set used to train them consist of matrices, which are grids of numbers that store data. With LLMs, these are called weight matrices and are numerical representations of word patterns from the text corpora fed to models during training
Caldera compresses compresses matrices and datasets. It uses a low-precision representation of data, reducing the number of bits, paring down storage space, improving processing speed and optimising energy efficiency.
The algorithm also uses low-rank adaptation, simplifying a large weight matrix by representing it using fewer dimensions or components, reducing its complexity while retaining essential information by reducing redundancies in the LLM weight matrices (unnecessary or repetitive information that can be removed or simplified without significantly impacting model performance).
“I think it’s encouraging and a bit surprising that we were able to get such good performance in this compression scheme,” said Goldsmith, who also holds the position of Arthur LeGrand Doty Professor of Electrical and Computer Engineering.. “By taking advantage of the weight matrix rather than just using a generic compression algorithm for the bits that are representing the weight matrix, we were able to do much better.”
The team tested their technique using Llama 2 and Llama 3, Meta AI's open-source LLMS, to find it offers performance improvements of up to 5% on benchmark tasks, including determining the logical order of two statements or answering questions involving physical reasoning, such as how to separate an egg white from a yolk or make a cup of tea.
“I think it’s encouraging and a bit surprising that we were able to get such good performance in this compression scheme,” said Goldsmith, who moved to Princeton from Stanford Engineering in 2020. “By taking advantage of the weight matrix rather than just using a generic compression algorithm for the bits that are representing the weight matrix, we were able to do much better.”
A small LLM compressed like this is useful for situations that don't require high precision, which rules out mission-critical tasks in heavily regulated industries like finance. However, it can be trained on edge devices like a laptop or smartphone, improving security posture and reducing the risk of a data breach or unauthorised access to confidential information by removing the need to share sensitive data with third-party providers.
On-device AI
To squeeze LLMs onto everyday devices, they must initially be compressed to fit on consumer-grade GPUs.
Whilst lean language models do not necessarily require a connection to a data centre and do not expend as much energy as their larger cousins, users will certainly notice an impact on their device battery.
“You won’t be happy if you are running an LLM and your phone drains out of charge in an hour,” said coauthor Rajarshi Saha, a Stanford Engineering PhD student.
“I wouldn’t say that there’s one single technique that solves all the problems," he continued. "What we propose in this paper is one technique that is used in combination with techniques proposed in prior works. And I think this combination will enable us to use LLMs on mobile devices more efficiently and get more accurate results.”
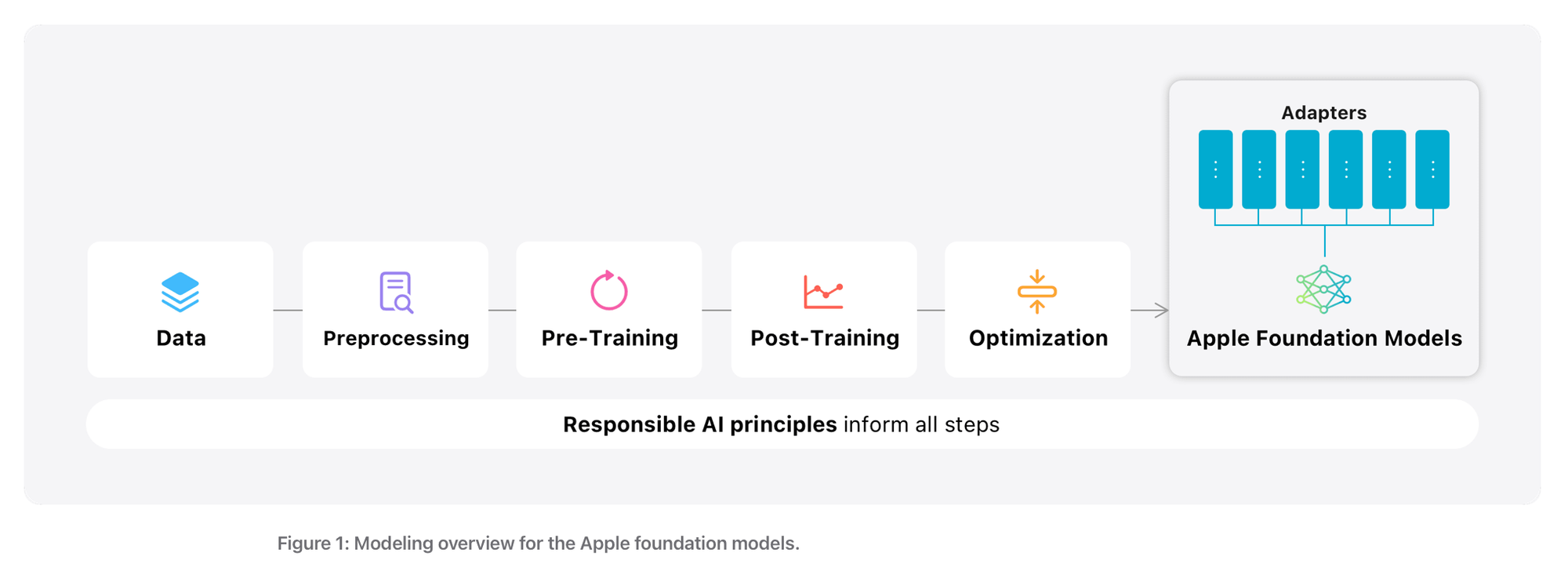
The life of Phi: Small models at Microsoft and Apple
Apple has developed small models that are trained on as few as three billion parameters. Apple Intelligence puts AI on users' devices, doing tasks like correcting and proofreading text without an internet connection.
It can also "enlist help from larger, more complex models in the cloud" via a service called Private Cloud Compute.
Microsoft is also experimenting with lean language models. Its "tiny but mighty" Phi 3 models are trained on as little as 3.8 billion parameters - a fraction of the estimated 1.8 trillion used to train GPT3.
"Small language models are well suited for organizations looking to build applications that can run locally on a device (as opposed to the cloud) and where a task doesn’t require extensive reasoning or a quick response is needed," Microsoft wrote. "Large language models are more suited for applications that need orchestration of complex tasks involving advanced reasoning, data analysis and understanding of context.
"Small language models also offer potential solutions for regulated industries and sectors that encounter situations where they need high quality results but want to keep data on their own premises."
Microsoft said its lean language models deliver "outsized results in a tiny package" thanks to a "highly selective approach to training data". In one experiment, it moved away from gorgings it models on "massive amounts of data from the internet" and used a dataset of just 3,000 words taken from the bedtime stories an engineer read to his daughter.
The model was asked to create a children’s story using one noun, verb, and adjective from the list, repeating the process millions of times. This created a dataset called “TinyStories”, which can be used to train very small language models of around 10 million parameters.
Andrej Karpathy, former director of AI for Tesla and a member of the founding team at OpenAI, has previously said that LLM competition is "intensifying backwards".
He wrote: "My bet is that we'll see models that 'think' very well and reliably that are very very small.... The reason current models are so large is because we're still being very wasteful during training - we're asking them to memorize the internet."
Have you got a story to share? Get in touch and let us know.



